CI/CD Pipeline for Large Language Models (LLMs) and GenAI

Introduction:
Large Language Models (LLMs) have transformed industries with their capabilities to generate meaningful text, answer intricate questions, and streamline workflows. However, deploying these models into production goes beyond training — it requires a solid Continuous Integration and Continuous Deployment (CI/CD) pipeline. This pipeline ensures that LLMs remain scalable, reliable, and efficient.

In this article, we’ll outline the six essential phases of a CI/CD pipeline specifically tailored for LLM applications, ensuring a smooth, reliable deployment process and ongoing monitoring.
1. Version Control & Code Management
Effective version control is the foundation of any CI/CD pipeline. It allows teams to maintain consistent records of code, datasets, and model configurations, ensuring reproducibility and smooth collaboration.
Best Practices:
- Utilize platforms like GitHub, GitLab, or Bitbucket for managing repositories.
- Implement structured branching strategies:
main→ Stable, production-ready code.dev→ Experimental development and testing.staging→ Validation before production.- Store large model files separately using tools like DVC (Data Version Control) or cloud-based storage solutions (AWS S3, Google Cloud Storage).
- Apply pre-commit hooks to maintain coding standards before changes are committed.

Example: Instead of directly committing heavy model files, manage their metadata in Git and store the actual files in an external object storage service. This ensures a clean repository while maintaining easy access to model versions.
2. Automated Testing
LLMs are sensitive to subtle changes. Comprehensive automated testing is crucial to identify and address any issues that could lead to unexpected outputs or degraded performance.
Types of Testing:
- Unit Tests: Validate small components, such as tokenization methods or individual preprocessing functions.
- Integration Tests: Ensure different parts of the system, including APIs, databases, and models, work together as intended.
- Regression Tests: Confirm that new updates don’t degrade performance or accuracy.
- Inference Tests: Benchmark model outputs against known datasets to maintain consistency.
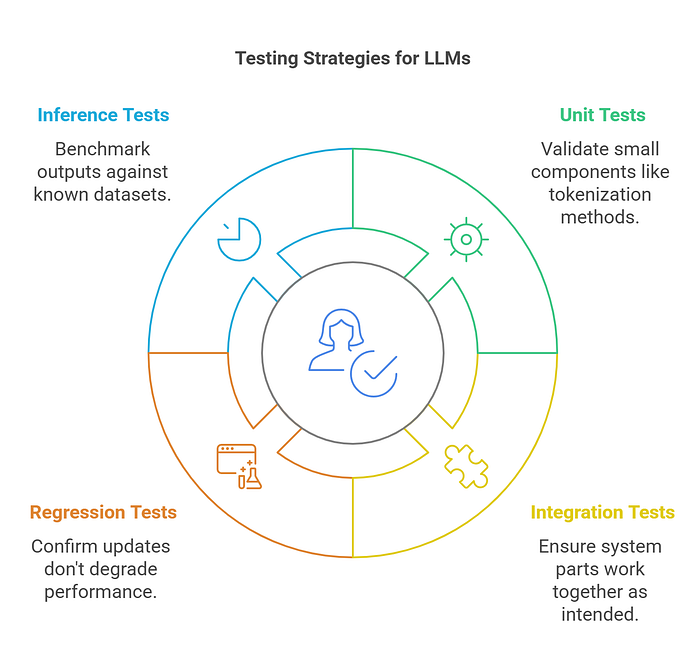
Example: A regression test checks that a summarization model still produces a coherent and accurate summary after prompt adjustments.
3. Continuous Integration (CI)
Continuous Integration automates the process of building, testing, and validating code changes. It helps detect and resolve issues early, reducing time to production.
CI Pipeline Steps:
- Automatically trigger builds upon Git pushes via tools like GitHub Actions, GitLab CI, or Jenkins.
- Create a clean environment using Docker or virtual environments to ensure consistency.
- Use caching to speed up dependency installation.
- Run automated tests (unit, integration, and inference) to catch errors quickly.
- Package models and code into Docker containers for easy deployment.
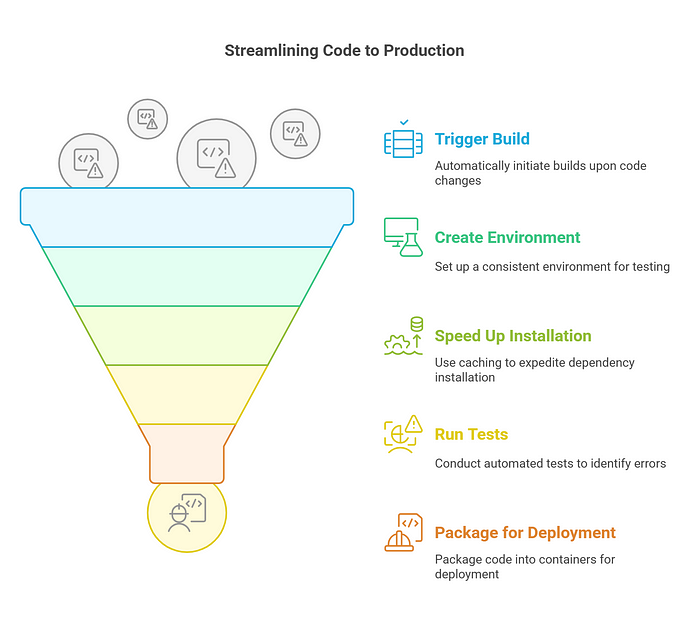
Example: A CI workflow runs unit tests and builds a new container image whenever a developer pushes changes to the dev branch, ensuring the code is stable before merging to main.
4. Model Training & Fine-Tuning
LLMs often require ongoing fine-tuning. Automating the training pipeline ensures consistency, reduces human error, and accelerates iteration cycles.
Training Pipeline Steps:
- Preprocess new data, ensuring it’s clean and correctly formatted.
- Train or fine-tune models on distributed frameworks like PyTorch Lightning or TensorFlow.
- Validate performance using established benchmarks and metrics (e.g., BLEU, ROUGE).
- Version new model weights and related metadata.
- Push trained models to repositories like Hugging Face, MLflow, or internal registries.
Scaling Training Jobs:
- Leverage distributed training with Kubernetes and Kubeflow.
- Use cloud-based resources (e.g., AWS SageMaker, GCP AI Platform) for scalability.
- Automate hyperparameter optimization using tools like Optuna or Ray Tune.
Example: A chatbot model is fine-tuned monthly with recent user interactions. This ongoing training helps maintain relevance and improve response quality over time.
5. Continuous Deployment (CD)
A well-structured deployment strategy ensures that updated models can be safely rolled out without disrupting the user experience.
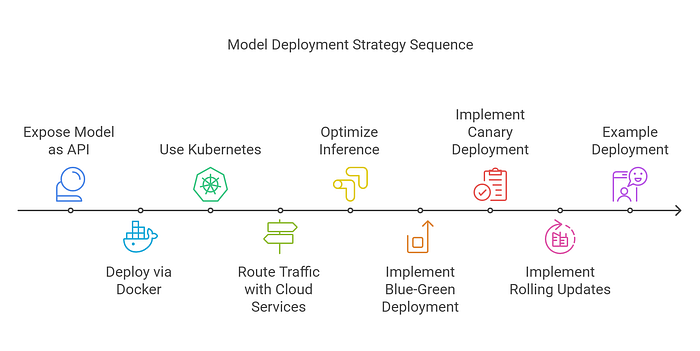
Deployment Strategies:
- Blue-Green Deployment: Run old and new versions side-by-side, gradually shifting traffic to the new version.
- Canary Deployment: Introduce the new version to a small user subset, monitoring for issues before full rollout.
- Rolling Updates: Deploy updates in small batches, minimizing the risk of downtime.
Deployment Workflow:
- Expose the model as an API using frameworks like FastAPI or Flask.
- Deploy via Docker containers and Kubernetes clusters.
- Utilize cloud services (AWS API Gateway, Cloudflare Workers) to handle traffic routing.
- Implement inference optimizations (TensorRT, ONNX Runtime) to improve performance.
Example: A sentiment analysis model is gradually deployed to 10% of users in a canary release. After confirming stability, it is rolled out to all users without downtime.
6. Monitoring & Rollback Mechanisms
Continuous monitoring ensures that deployed models perform as expected. If issues arise, the pipeline can quickly revert to a previous stable state.
Key Metrics to Monitor:
- Latency: How quickly the model responds to requests.
- Token Usage: Tracks resource consumption.
- Drift Detection: Identifies shifts in data patterns that could degrade model performance.
- Error Rate: Monitors unexpected or incorrect outputs.
Monitoring Tools:
- Prometheus and Grafana for real-time metric dashboards.
- ELK Stack (Elasticsearch, Logstash, Kibana) for log aggregation and analysis.
- OpenTelemetry for tracing API performance.
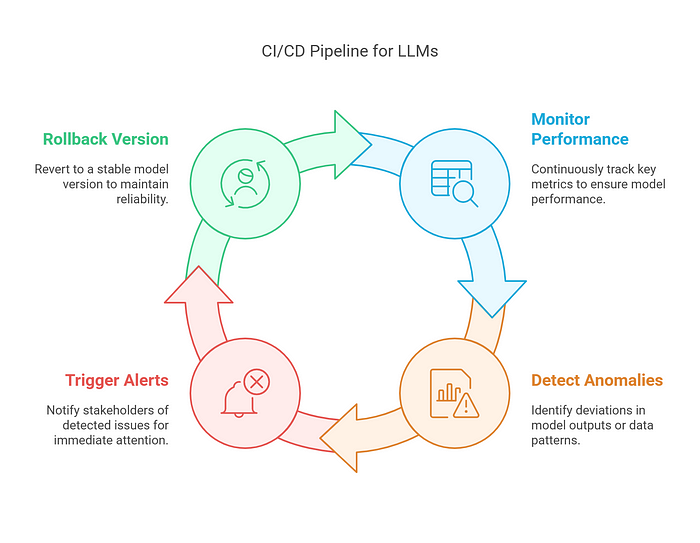
Example: If a newly deployed LLM generates incoherent responses, the pipeline detects the anomaly, triggers an alert, and rolls back to the prior stable version.
Conclusion:
A robust CI/CD pipeline for LLMs streamlines the process of deploying, testing, and updating these powerful models. By following these six key phases — version control, automated testing, continuous integration, training, deployment, and monitoring — organizations can ensure reliable, efficient, and scalable LLM applications.
