Apache Spark Interview Questions and Answers

What is Apache Spark?
- Apache Spark is a unified analytics engine for large-scale data processing. It is open-source and provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Spark offers high-level APIs in Java, Scala, Python, and R, and includes built-in modules for SQL, streaming, machine learning (MLlib), and graph processing (GraphX). Its key feature is in-memory computation, which enables much faster processing compared to traditional disk-based frameworks like Hadoop MapReduce. Spark can run on various cluster managers like YARN, Mesos, Kubernetes, and its own standalone mode.
Explain the differences between RDD, DataFrame, and Dataset in Spark.
- RDD (Resilient Distributed Dataset):
- RDD is Spark’s core abstraction for distributed data. It is a low-level, immutable, fault-tolerant distributed collection of objects that can be operated in parallel. Operations on RDDs are transformations (like map, filter) or actions (like collect, count).
- Pros: More control over the data, works well for unstructured data, fault tolerance using lineage, flexible.
- Cons: Lacks optimization for query execution and does not support optimization features like predicate pushdown.
- DataFrame:
- DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a DataFrame in Python (pandas). DataFrames provide optimizations via Spark’s Catalyst query optimizer, which allows them to run faster compared to RDDs.
- Pros: High-level abstraction, supports SQL queries, and better performance through optimization.
- Cons: Less type safety as column names are not checked at compile-time (in Scala/Java).
- Dataset:
- Dataset is a combination of RDD and DataFrame API, introduced in Spark 1.6, providing the benefits of both. It is a distributed collection of typed objects, allowing you to work with custom Java or Scala objects with the added benefits of type-safety (compile-time type checking) and Catalyst optimizations.
- Pros: Type-safe, object-oriented API with the optimizations of DataFrame.
- Cons: Not available in Python, and sometimes slower for unstructured data compared to RDDs.
What are transformations and actions in Spark? Provide examples of each.
- Transformations: These are operations that create a new RDD or DataFrame from an existing one, but they are lazy, meaning they don’t compute their results immediately. Instead, they build up a logical execution plan which is only executed when an action is triggered.
- Examples:
- map(): Applies a function to each element and returns a new RDD.
- filter(): Returns an RDD containing only the elements that satisfy a given predicate.
- flatMap(): Similar to map() but allows returning multiple elements for each input element.
- Actions: These are operations that trigger the execution of the transformations and return a value to the driver program or write data to an external storage system.
- Examples:
- count(): Returns the number of elements in the RDD.
- collect(): Returns all the elements of the dataset to the driver program.
- saveAsTextFile(): Writes the elements of an RDD to a text file.
Describe lazy evaluation in Spark. Why is it beneficial?
- Lazy evaluation means that Spark does not immediately execute the transformations (such as map() or filter()) applied to an RDD or DataFrame. Instead, Spark builds a Directed Acyclic Graph (DAG) of these transformations. When an action is called (like count() or collect()), Spark evaluates the DAG and optimizes the execution plan before actually performing the computation.
- Benefits:
- Optimization: By building the execution plan in advance, Spark can optimize the entire computation pipeline, reducing unnecessary data shuffling and combining operations.
- Fault tolerance: Lazy evaluation makes it easier to recompute only lost data from lineage when a partition fails.
- Efficiency: Operations are only performed when needed, so transformations that are never used by an action will not be computed, saving time and resources.
What is the purpose of caching in Spark? When should you consider caching a DataFrame?
- Caching (or persisting) stores the intermediate results of a DataFrame or RDD in memory across the cluster, so that future actions on the same dataset can be performed much faster without recomputation.
- Purpose:
- Improves performance when a DataFrame or RDD is reused multiple times in the same job, as the data is kept in memory rather than recomputed from the original source.
When to use caching:
- If a DataFrame or RDD is used repeatedly in multiple actions.
- In iterative algorithms like those in machine learning or graph processing where the same dataset is processed repeatedly.
- Example: When performing multiple queries on the same dataset, caching prevents re-reading and re-processing the same data from disk.
Explain the concept of partitioning in Spark.
- Partitioning refers to dividing a large dataset into smaller, more manageable chunks (partitions) that are spread across the cluster for parallel processing. Spark processes each partition on a different node, allowing it to process large datasets in parallel.
- Benefits:
- Increased parallelism and speed.
- Improved fault tolerance since each partition can be recomputed independently if lost.
- Manual partitioning:
- Users can control how data is partitioned by specifying the number of partitions or by applying custom partitioning logic (especially for key-value RDDs).
What is the difference between coalesce and repartition in Spark?
- repartition(): Increases or decreases the number of partitions and always involves a full shuffle of the data. It’s used when you want to evenly distribute data across all partitions.
- Example: df.repartition(100) creates 100 partitions.
- coalesce(): Reduces the number of partitions without a full shuffle. It’s more efficient than repartition() for downsizing the number of partitions.
- Example: df.coalesce(10) reduces the number of partitions to 10, only reshuffling data if necessary.
What is the difference between cache() and persist() methods in Spark?
- cache(): Stores the DataFrame or RDD in memory (the default storage level is MEMORY_ONLY). If the dataset doesn’t fit in memory, some partitions may be recomputed.
- persist(): Allows you to specify the storage level (such as MEMORY_AND_DISK, DISK_ONLY, etc.) based on your needs. This gives more control over how data is stored.
- Example: Use persist(StorageLevel.MEMORY_AND_DISK) when the dataset is too large to fit in memory.
How does Spark handle schema inference for DataFrames?
- Spark can automatically infer the schema of data when reading from structured file formats such as CSV, JSON, or Parquet. For example, when you read a JSON file, Spark will inspect the first few rows and determine the data types of each field. However, for performance-critical applications, it is often recommended to provide the schema explicitly to avoid the overhead of schema inference.
- Describe the stages of execution in Spark.
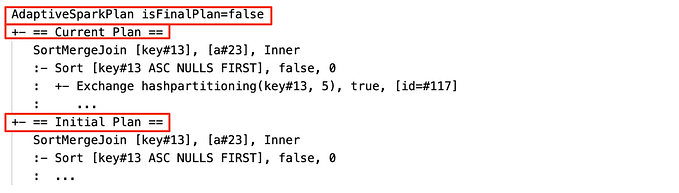
- Spark breaks a job into stages. Each stage corresponds to a set of transformations with narrow dependencies (e.g., map(), filter()) that can be executed in parallel. A stage boundary occurs when there’s a wide transformation (e.g., groupBy(), reduceByKey()), which requires a shuffle of data between the nodes. Each stage is further divided into tasks, with each task corresponding to a partition of the data.
Explain the role of DAG (Directed Acyclic Graph) in Spark’s execution model.
- A DAG is a logical graph that represents the flow of computations in Spark. It captures all transformations on RDDs or DataFrames in the form of a directed acyclic graph where each vertex is an RDD and edges represent transformations. Spark uses this DAG to optimize and schedule execution across a cluster, avoiding unnecessary recomputations and minimizing shuffles.
What is the Catalyst optimizer in Spark SQL? How does it optimize query execution?
- Catalyst is Spark SQL’s optimization engine. It performs rule-based optimization to transform logical query plans into optimized physical plans. Catalyst includes techniques like predicate pushdown, column pruning, and join optimizations. It allows Spark to convert logical plans into highly optimized physical plans that can be executed efficiently.
Discuss the use of window functions in Spark SQL. Provide examples of scenarios where they are beneficial.
- Window functions in Spark SQL allow you to perform calculations across a set of table rows that are somehow related to the current row. Unlike aggregate functions, window functions do not group the result set into a single row per group. They are beneficial for running totals, ranking, and computing moving averages.
- Example: Calculating a running total of sales over a date range.
How does Spark handle fault tolerance?
- Spark ensures fault tolerance using lineage and DAG. Every RDD has a lineage that records the sequence of transformations that produced it. If any partition of an RDD is lost, Spark can recompute it from the original data using the lineage information.
Explain the concept of Data lineage in Spark.
- Data lineage refers to the metadata that records the history of transformations that were applied to create an RDD. It allows Spark to recompute lost data partitions in case of failures, making it fault-tolerant.
What are broadcast variables in Spark? When and how should you use them?
- Broadcast variables allow a programmer to cache a read-only copy of a large dataset on every node in the cluster. This avoids sending large datasets to each task, minimizing network I/O.
- Use them when you have a large, read-only dataset that you need to use in multiple tasks, like a lookup table for joins.
Describe the different types of joins supported by Spark DataFrames.
- Spark DataFrames support various types of joins, including:
- Inner Join: Returns only matching rows between both DataFrames.
- Left/Right Outer Join: Returns all rows from the left/right DataFrame, with nulls for missing matches.
- Full Outer Join: Returns all rows when there is a match in either DataFrame.
- Cross Join: Returns the Cartesian product of two DataFrames.
- Semi/Anti Join: Returns rows from the left DataFrame that have (or don’t have) matches in the right DataFrame.
How does Spark perform shuffle operations in DataFrames?
- Shuffle occurs when Spark needs to redistribute data across partitions, typically during wide transformations like groupBy(), join(), or reduceByKey(). Shuffle involves reading data from each partition, redistributing it to the appropriate nodes, and then writing the shuffled data to new partitions.
What is the significance of checkpointing in Spark Streaming?
- Checkpointing is essential in Spark Streaming for fault tolerance. It saves RDD lineage information to reliable storage (e.g., HDFS). If the streaming application fails, it can restart from the last checkpoint to avoid recomputing data from the beginning.
How would you approach handling a large dataset that doesn’t fit into memory?
- Use disk-based storage through the persist() method with the MEMORY_AND_DISK storage level. Also, use efficient file formats like Parquet or ORC and partition the data to reduce memory usage. You could also use bucketing to optimize joins.
How are the initial number of partitions calculated in a DataFrame?
- The number of partitions in a DataFrame is typically determined by the data source. For example, if reading from HDFS, it is based on the HDFS block size. When using repartition() or coalesce(), you can manually specify the number of partitions.
Explain strategies for ensuring fault tolerance in a Spark Streaming application consuming data from Kafka.
- Use WAL (write-ahead logs) to log data received from Kafka. Enable checkpointing to HDFS or a reliable storage system. Also, make use of idempotent writes to ensure that duplicate messages are not processed multiple times.
How would you optimize joining two large datasets in Spark, with one dataset exceeding memory capacity?
- Use a broadcast join if one dataset is small enough to fit into memory. If both datasets are large, consider partitioning them on the join key to avoid shuffling all data, or use bucketing to optimize the join.
Describe the process of identifying and addressing performance bottlenecks in a slow-running Spark job.
- Use the Spark UI to identify stages and tasks that are taking longer to execute. Look at the shuffle read/write size, task distribution, and memory usage. Consider repartitioning, caching, or adjusting memory configurations to address issues like data skew or excessive shuffling.
How would you distribute a large dataset efficiently across multiple nodes in a Spark cluster for parallel processing?
- Use repartition() to evenly distribute data across the nodes, ensuring each node gets a balanced portion of the data. Also, ensure the partitioning strategy is aligned with the data processing logic to minimize shuffling.
Discuss techniques for optimizing iterative computations in Spark jobs, such as machine learning models or graph algorithms.
- Caching or persisting intermediate results is crucial in iterative algorithms like ML models, where the same data is processed multiple times. You can also use specialized libraries like MLlib, which are optimized for Spark’s execution model.
How do you handle data skewness in Spark DataFrames? What are the implications of skewed data on performance?
- Data skew occurs when certain partitions have significantly more data than others, leading to uneven task distribution and longer execution times. You can address skewness by:
- Repartitioning: Redistribute data more evenly across partitions.
- Salting: Add random keys to the join keys to spread out the data more evenly during joins.
- Handling skewed keys: Use techniques like broadcast joins for small datasets or partition pruning.
Explain the concept of broadcast joins in Spark. How do they work internally, and when should you use them?
- Broadcast joins are used when one of the DataFrames is small enough to fit into memory. Spark sends a copy of the smaller DataFrame to all nodes in the cluster, allowing each node to perform the join locally without shuffling the larger dataset.
- Example: df1.join(broadcast(df2), “id”).
Describe Spark’s memory management system. How does it handle out-of-memory errors?
- Spark divides its memory into storage memory and execution memory. Storage memory is used for caching RDDs, while execution memory is used for tasks like shuffles, joins, and aggregations. When a job runs out of memory, Spark tries to spill data to disk. If there isn’t enough disk space, it will throw an out-of-memory error.
- Techniques to manage memory include adjusting the number of partitions, using appropriate storage levels, and tuning Spark’s memory configurations (e.g., spark.executor.memory).
What is the difference between partitioning and bucketing in Spark?
- Partitioning: Divides data into directories based on a partition column. It helps with pruning, as only relevant partitions are read during a query.
- Bucketing: Divides data into a fixed number of buckets based on a hash of a column, optimizing joins and aggregations. Unlike partitioning, bucketing is physically distributed into files, each representing a bucket.